Intel - oneDNN
oneDNN実行プロバイダー
Section titled “oneDNN実行プロバイダー”旧称「DNNL」
Intel oneDNN実行プロバイダーを使用して、Intel® Math Kernel Library for Deep Neural Networks(Intel® DNNL)最適化プリミティブでONNX Runtimeのパフォーマンスを加速します。
Intel® oneAPI Deep Neural Network Libraryは、深層学習アプリケーション向けのオープンソースパフォーマンスライブラリです。このライブラリは、Intel®アーキテクチャとIntel® Processor Graphics Architecture上で深層学習アプリケーションとフレームワークを加速します。Intel DNNLには、CおよびC++インターフェースで深層ニューラルネットワーク(DNN)を実装するために使用できるベクトル化およびスレッド化されたビルディングブロックが含まれています。
ONNX Runtime用のoneDNN実行プロバイダー(EP)は、IntelとMicrosoftのパートナーシップによって開発されています。
ビルド手順については、ビルドページを参照してください。
DNNLExecutionProvider実行プロバイダーは、推論セッションで有効にするためにONNX Runtimeに登録する必要があります。
Ort::Env env = Ort::Env{ORT_LOGGING_LEVEL_ERROR, "Default"};Ort::SessionOptions sf;bool enable_cpu_mem_arena = true;Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_Dnnl(sf, enable_cpu_mem_arena));C APIの詳細はこちらにあります。
Python
Section titled “Python”DNNL実行プロバイダーでビルドされたONNX RuntimeのPythonホイールを使用する場合、CPU実行プロバイダーよりも自動的に優先されます。Python APIの詳細はこちらにあります。
サブグラフ最適化
Section titled “サブグラフ最適化”DNNLは、AVX512を使用したベクトル演算を活用するためにブロック化レイアウト(例:チャネルが16でブロック化されたnhwc - nChw16c)を使用します。最高のパフォーマンスを得るために、リオーダー(例:Nchw16cからnchw)を避け、ブロック化レイアウトを次のプリミティブに伝播させます。
サブグラフ最適化は以下のステップで実現されます。
- ONNX Runtimeグラフを解析し、サブグラフの内部表現を作成します。
- サブグラフ演算子(DnnlFunKernel)がDNNLノードを反復処理し、DNNLカーネルのベクトルを作成します。
- DnnlFunKernelの計算関数が反復処理し、ベクトル内のDNNLプリミティブにデータをバインドし、実行用にベクトルを送信します。
サブグラフ(IR)内部表現
Section titled “サブグラフ(IR)内部表現”DnnlExecutionProvider::GetCapability()はONNXモデルグラフを解析し、DNNL演算子のサブグラフのIR(内部表現)を作成します。 各サブグラフには、すべてのDnnlNodesのベクトルDnnlNodes、入力、出力、および属性が含まれています。同じ名前の属性が存在する可能性があります。そのため、属性名にノード名とそのインデックスをプレフィックスとして付けます。 サブグラフの一意IDが属性として設定されます。
DnnlNodeは入力と出力へのインデックスと親ノードへのポインターを持ちます。DnnlNodeはデータの並び替えを避けるために、親から直接ブロック化メモリを読み取ります。

サブグラフクラス
Section titled “サブグラフクラス”DnnlConv、DnnlPoolなどのプリミティブは、DnnlKernelベースクラスから派生しています。
以下のUML図はサブグラフクラスを示しています。
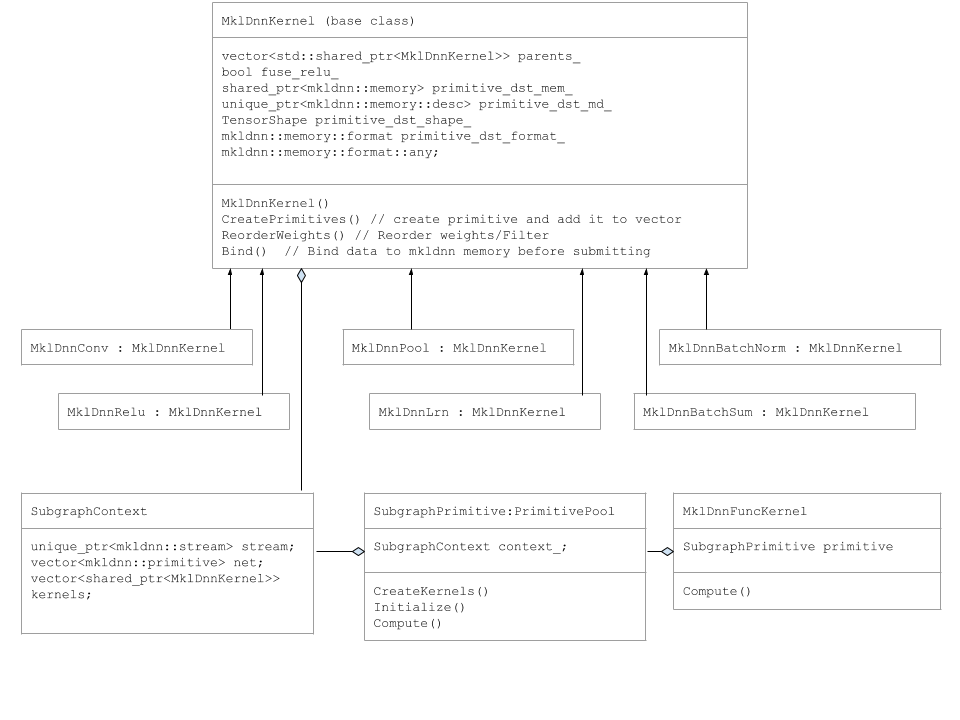
サブグラフ実行
Section titled “サブグラフ実行”DnnlExecutionProvider::Compute()関数はDnnlFuncKernelを作成し、そのCompute関数を呼び出します。
DnnlFuncKernel::Compute関数はSubgraphPrimtiveプールを作成し、オブジェクトをマップに追加します。
SubgraphPrimtiveコンストラクターは以下のメンバー関数を呼び出します:
SubgraphPrimitve::CreatePrimitives() for (auto& mklnode : mklnodes) { if (mklnode.name == "Conv") { kernel.reset(new DnnlConv()); kernels.push_back(kernel); } else if (mklnode.name == "BatchNormalization-Relu") { kernel.reset(new DnnlBatchNorm()); context_.kernels.push_back(kernel); } else if (mklnode.name == "MaxPool") { kernel.reset(new DnnlPool()); context_.kernels.push_back(kernel); } . . .CreatePrimitivesメソッドでは、DnnlNodesを反復処理してDnnlKernelオブジェクトを作成し、DNNLプリミティブをベクトルに追加します。また、属性も読み取ります。これは最初の反復時に一度だけ実行されます。
SubgraphPrimitve::Compute() for (auto& kernel : kernels) { kernel->Bind(input_tensors, output_tensors); } stream->submit(net);SubgraphPrimitve::Compute()メソッドでは、Dnnlカーネルを反復処理して入力データをバインドします。その後、プリミティブのベクトルをDNNLストリームに送信します。
サポート範囲
Section titled “サポート範囲”サポートされているOS
- Ubuntu 16.04
- Windows 10
- Mac OS X
サポートされているバックエンド
- CPU