モバイルパフォーマンスの調整(ORT <1.10のみ)
重要:この情報はONNX RUNTIMEバージョン1.10以前にのみ適用されます。新しいバージョンを使用してください。
Section titled “重要:この情報はONNX RUNTIMEバージョン1.10以前にのみ適用されます。新しいバージョンを使用してください。”ONNX Runtimeモバイルパフォーマンスチューニング
Section titled “ONNX Runtimeモバイルパフォーマンスチューニング”さまざまな最適化がパフォーマンスにどのように影響するかを学び、ORT形式のモデルでのパフォーマンステストの提案を得ます。
ONNX Runtime Mobileは、AndroidプラットフォームではNNAPI(NNAPI実行プロバイダー(EP)経由)を、iOSプラットフォームではCoreML(CoreML EP経由)を使用してORT形式のモデルを実行するために使用できます。
まず、ONNX Runtime MobileでのNNAPIの使用とONNX RuntimeでのCoreMLの使用の紹介詳細を確認してください。
重要事項: このページの例では、簡潔にするためにNNAPI EPを参照しています。この情報はCoreML EPにも同様に適用されるため、以下の「NNAPI」への言及はすべて「CoreML」に置き換えることができます。
NNAPI対応ORT形式モデルの作成と同様に、CoreML対応ORT形式モデルの作成のサポートは、ONNX Runtimeバージョン1.9で追加されました。
- TOC
1. ONNXモデル最適化の例
Section titled “1. ONNXモデル最適化の例”ONNX Runtimeは、推論パフォーマンスを向上させるためにONNXモデルに最適化を適用します。これらの最適化は、ORT形式のモデルをエクスポートする前に行われます。利用可能な最適化の詳細については、グラフ最適化のドキュメントを参照してください。
さまざまな最適化レベルがモデル内のノードにどのように影響するかを理解することが重要です。これにより、NNAPIまたはCoreMLを使用してモデルのどの程度を実行できるかが決まります。
基本
_基本_最適化は、冗長なノードを削除し、定数畳み込みを実行します。これらの最適化では、モデルの変更時にONNX演算子のみが使用されます。
拡張
_拡張_最適化は、1つ以上の標準ONNX演算子をカスタムの内部ONNX Runtime演算子に置き換えて、パフォーマンスを向上させます。各最適化には、有効なEPのリストがあります。そのEPに割り当てられているノードのみを置き換え、置換ノードは同じEPを使用して実行されます。
レイアウト
_レイアウト_最適化は、ハードウェア固有の場合があり、ONNXで使用されるNCHW画像レイアウトとNHWCまたはNCHWc形式間の内部変換を含みます。これらは、「all」の最適化レベルで有効になります。
- 1.8より前のONNX Runtimeバージョンでは、ORT形式のモデルを作成するときにレイアウト最適化を使用しないでください。
- ONNX Runtimeバージョン1.8以降では、ハードウェア固有の最適化が自動的に無効になるため、レイアウト最適化を有効にすることができます。
最適化されたORT形式モデルを作成するときの最適化の結果
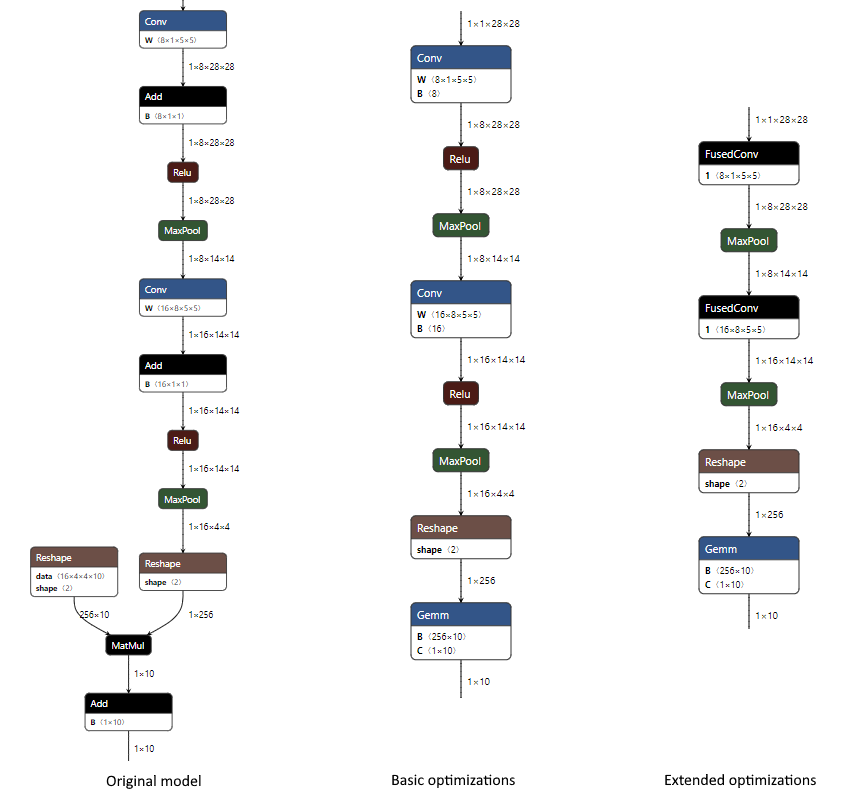
Section titled “最適化されたORT形式モデルを作成するときの最適化の結果”以下は、CPU EPのみが有効になっているMNISTモデルに適用された場合の、_基本_および_拡張_最適化で発生する変更の例です。最適化レベルは、ORT形式モデルの作成時に指定されます。
- _基本_レベルでは、ConvノードとAddノードを組み合わせ(加算はConvへの「B」入力を介して行われます)、MatMulノードとAddノードを単一のGemmノードに組み合わせ(加算はGemmへの「C」入力を介して行われます)、定数畳み込みを行ってReshapeノードの1つを削除します。
python <ORTリポジトリルート>/tools/python/convert_onnx_models_to_ort.py --optimization_level basic /dir_with_mnist_onnx_model
- _拡張_レベルでは、さらに内部ONNX Runtime FusedConv演算子を使用してConvノードとReluノードを融合します。
python <ORTリポジトリルート>/tools/python/convert_onnx_models_to_ort.py --optimization_level extended /dir_with_mnist_onnx_model
NNAPI EPで最適化されたORT形式モデルを実行した結果
Section titled “NNAPI EPで最適化されたORT形式モデルを実行した結果”実行時にNNAPI EPが登録されている場合、ロードされたモデル内で実行できるノードを選択する機会が与えられます。その際、CPUとNNAPIの間でデータをコピーしてノードを実行するオーバーヘッドを最小限に抑えるために、できるだけ多くのノードをグループ化します。各ノードのグループはサブグラフと見なすことができます。各サブグラフのノードが多く、サブグラフが少ないほど、パフォーマンスは向上します。
サブグラフごとに、NNAPI EPは元のノードの処理を複製するNNAPIモデルを作成します。このNNAPIモデルを実行し、CPUとNNAPIの間で必要なデータコピーを実行する関数を作成します。ONNX Runtimeは、ロードされたモデルの元のノードを、この関数を呼び出す単一のノードに置き換えます。
NNAPI EPが登録されていない場合、またはノードを処理できない場合、ノードはCPU EPを使用して実行されます。
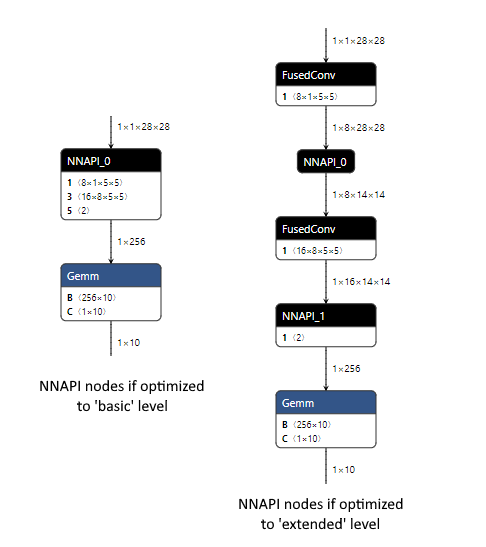
以下は、NNAPI EPが登録されている場合に実行時にORT形式のモデルに何が起こるかを比較したMNISTモデルの例です。
_基本_レベルの最適化は、ONNX演算子のみを使用するモデルになるため、NNAPIはConv、Relu、およびMaxPoolノードを実行できるため、モデルの大部分を処理できます。これは、NNAPIが処理できるすべてのノードが接続されているため、単一のNNAPIモデルで行われます。単一のNNAPIノードのCPUとNNAPI間のデバイスコピーのオーバーヘッドは、NNAPIを使用して一度に複数の操作を実行することで節約される時間を超える可能性が高いため、このモデルでNNAPIを使用するとパフォーマンスが向上することが期待されます。
_拡張_レベルの最適化では、カスタムのFusedConvノードが導入されますが、NNAPI EPは、NNAPIが処理できるONNX演算子を使用しているノードのみを受け入れるため、これを無視します。これにより、NNAPIを使用する2つのノードが作成され、それぞれが単一のMaxPool操作を処理します。このモデルのパフォーマンスは、CPUとNNAPI間のデバイスコピーのオーバーヘッド(2つのNNAPIノードのそれぞれの前後に必要)が、NNAPIを使用して毎回単一のMaxPool操作を実行することで節約される時間を超える可能性が低いため、悪影響を受ける可能性があります。NNAPI EPを登録しないことで、モデル内のすべてのノードがCPU EPを使用して実行されるようにすることで、より良いパフォーマンスが得られる場合があります。
2. 初期パフォーマンステスト
Section titled “2. 初期パフォーマンステスト”最適な最適化設定はモデルによって異なります。NNAPIでパフォーマンスが向上するモデルもあれば、そうでないモデルもあります。パフォーマンスはモデル固有であるため、パフォーマンステストを実行して、モデルに最適な組み合わせを決定する必要があります。
パフォーマンステストを実行することをお勧めします。
- NNAPIを有効にし、_基本_レベルの最適化で作成されたORT形式モデルを使用する
- NNAPIを無効にし、_拡張_または_すべて_レベルの最適化で作成されたORT形式モデルを使用する
- ONNX Runtimeバージョン1.8以降では_すべて_を使用し、以前のバージョンでは_拡張_を使用します
ほとんどのシナリオでは、これら2つのアプローチのいずれかが最高のパフォーマンスをもたらすと予想されます。
基本_レベルの最適化とNNAPIを使用したORT形式モデルが同等以上のパフォーマンスをもたらす場合、NNAPI対応のORT形式モデルを作成することでパフォーマンスをさらに向上させることができる_場合があります。このモデルの違いは、より高いレベルの最適化がNNAPIを使用して実行できないノードにのみ適用されることです。このカテゴリに分類されるノードがあるかどうかは、モデルによって異なります。
3. NNAPI対応ORT形式モデルの作成
Section titled “3. NNAPI対応ORT形式モデルの作成”NNAPI対応のORT形式モデルは、NNAPIを使用して実行できるONNXモデルのすべてのノードを保持し、残りのノードに_拡張_最適化を適用できるようにします。
MNISTモデルの場合、_基本_最適化が適用された後、赤色の網掛けのノードはそのまま保持され、緑色の網掛けのノードには_拡張_最適化を適用できることを意味します。
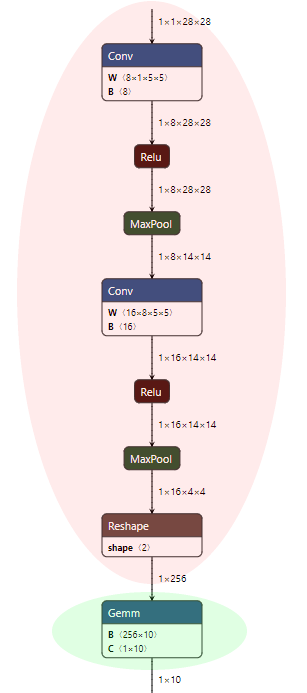
NNAPI対応のORT形式モデルを作成するには、次の手順に従ってください。
-
ソースからONNX Runtimeをビルドして、NNAPI EPを含むONNX Runtimeの「フル」ビルドを作成します。
このビルドはどのプラットフォームでも実行できます。NNAPI EPは、このプロセスにモデルの実行がないため、Android NNAPIライブラリなしでORT形式モデルを作成するために使用できるためです。ビルド時に、それらが欠落している場合は、ビルドフラグに
--use_nnapi --build_shared_lib --build_wheelを追加します。--minimal_buildフラグは追加しないでください。-
Windows :
<ONNX Runtimeリポジトリルート>\build.bat --config RelWithDebInfo --use_nnapi --build_shared_lib --build_wheel --parallel -
Linux:
<ONNX Runtimeリポジトリルート>/build.sh --config RelWithDebInfo --use_nnapi --build_shared_lib --build_wheel --parallel
注意: ONNX Runtimeバージョン1.10以前の場合、以前に演算子カーネルを削減した最小ビルドを実行したことがある場合は、「フル」ビルドを実行する前に
git reset --hardを実行して、演算子カーネルの除外が元に戻されていることを確認する必要があります。そうしないと、カーネルが見つからないためにONNX形式のモデルをロードできない場合があります。 -
-
ビルド出力ディレクトリからpythonホイールをインストールします。
- Windows : これは
build/Windows/<config>/<config>/dist/<package name>.whlにあります。 - Linux : これは
build/Linux/<config>/dist/<package name>.whlにあります。 パッケージ名は、プラットフォーム、pythonバージョン、およびビルドパラメータによって異なります。<config>は、ビルドコマンドの--configパラメータの値です。pip install -U build\Windows\RelWithDebIfo\RelWithDebIfo\dist\onnxruntime_noopenmp-1.7.0-cp37-cp37m-win_amd64.whl
- Windows : これは
-
標準の手順に従って
convert_onnx_models_to_ort.pyを実行し、NNAPIを有効にして(--use_nnapi)、最適化レベルを_拡張_または_すべて_に設定して(例:--optimization_level extended)、NNAPI対応のORT形式モデルを作成します。これにより、NNAPIが処理できないノードでより高いレベルの最適化を実行できます。python <ORTリポジトリルート>/tools/python/convert_onnx_models_to_ort.py --use_nnapi --optimization_level extended /models--use_nnapiを有効なオプションにするには、NNAPIが有効になっている「フル」ビルドのpythonパッケージをインストールする必要があります。作成されたこのORTモデルは、NNAPI EPを含む最小ビルドで使用できます。