モバイルへのデプロイ
ONNX Runtimeを使用してモバイルアプリケーションを開発する方法
Section titled “ONNX Runtimeを使用してモバイルアプリケーションを開発する方法”ONNX Runtimeは、モバイルアプリケーションに機械学習を追加するためのさまざまなオプションを提供します。このページでは、開発プロセスの流れを説明します。このセクションのチュートリアルも確認できます:
ONNX Runtimeモバイルアプリケーション開発フロー
Section titled “ONNX Runtimeモバイルアプリケーション開発フロー”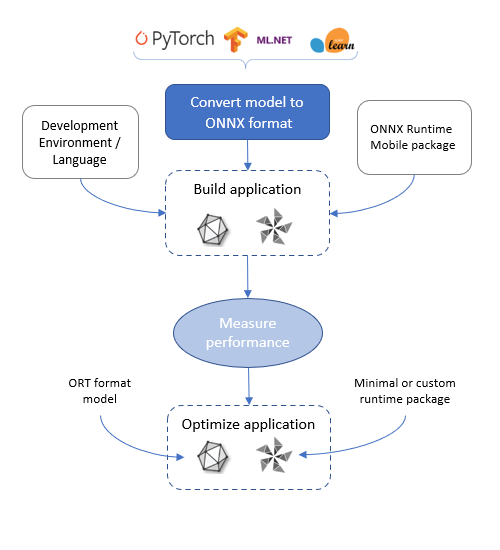
モデルを取得する
Section titled “モデルを取得する”モバイル機械学習アプリケーションを開発する最初のステップは、モデルを取得することです。
モバイルアプリのシナリオを理解し、そのシナリオに適したONNXモデルを取得する必要があります。たとえば、アプリは画像を分類するか、ビデオストリームで物体検出を行うか、テキストを要約または予測するか、数値予測を行うかです。
ONNX Runtimeモバイルで実行するには、モデルがONNX形式である必要があります。ONNXモデルは、ONNX model zooから取得できます。モデルがまだONNX形式でない場合は、コンバーターの1つを使用してPyTorch、TensorFlow、およびその他の形式からONNXに変換できます。
モデルはデバイスに読み込まれ、デバイス上で実行されるため、モデルはデバイスディスクに収まり、デバイスのメモリに読み込むことができる必要があります。
アプリケーションを開発する
Section titled “アプリケーションを開発する”モデルを取得したら、ONNX Runtime APIを使用して読み込み、実行できます。
使用する言語バインディングとランタイムパッケージは、選択した開発環境と開発対象のターゲットによって異なります。
- Android Java/C/C++: onnxruntime-androidパッケージ
- iOS C/C++: onnxruntime-cパッケージ
- iOS Objective-C: onnxruntime-objcパッケージ
- MAUI/XamarinでのAndroidおよびiOS C#: Microsoft.ML.OnnxRuntimeおよびMicrosoft.ML.OnnxRuntime.Managed
パッケージ固有の手順については、インストールガイドを参照してください。
上記のパッケージにはすべて、完全なONNX Runtime機能と演算子セット、およびONNX形式のサポートが含まれています。アプリケーションの開発を開始するために、これらを使用することをお勧めします。さらなる最適化が必要な場合があります。これらについては以下で詳しく説明します。
ターゲットプラットフォームに応じて、アプリで使用するハードウェアアクセラレータを選択できます:
- すべてのターゲットはCPUをサポートしており、これがデフォルトです
- Androidで実行されるアプリケーションは、NNAPIとXNNPACKもサポートしています
- iOSで実行されるアプリケーションは、CoreMLとXNNPACKもサポートしています
アクセラレータは、ONNX RuntimeではExecution Providerと呼ばれます。
モデルが量子化されている場合は、CPU Execution Providerから開始してください。モデルが量子化されていない場合は、XNNPACKから開始してください。これらはすべてがCPUで実行されるため、最も簡単で一貫性があります。
CPU/XNNPACKがアプリケーションのパフォーマンス要件を満たさない場合は、NNAPI/CoreMLを試してください。これらの実行プロバイダーでのパフォーマンスは、デバイスとモデルによって異なります。実行プロバイダーがサポートしていない演算子(たとえば、古いNNAPIバージョンが原因)を使用しているモデルが複数のパーティションに分割される場合、パフォーマンスが低下する可能性があります。
特定の実行プロバイダーは、ONNX Runtimeセッションが作成され、モデルが読み込まれるときにSessionOptionsで設定されます。詳細については、言語APIドキュメントを参照してください。
アプリケーションのパフォーマンスを測定する
Section titled “アプリケーションのパフォーマンスを測定する”ターゲットプラットフォームの要件に対してアプリケーションのパフォーマンスを測定します。これには以下が含まれます:
- アプリケーションバイナリサイズ
- モデルサイズ
- アプリケーションのレイテンシ
- 電力消費
アプリケーションが要件を満たしていない場合、適用できる最適化があります。
アプリケーションを最適化する
Section titled “アプリケーションを最適化する”モデルサイズを削減する
Section titled “モデルサイズを削減する”モデルサイズを削減する1つの方法は、モデルを量子化することです。これにより、重みが8ビットに削減されるため、32ビット重みを持つ元のモデルが約4分の1に削減されます。これを行う方法の手順については、ONNX Runtime量子化ガイドを参照してください。
モデルサイズを削減する別の方法は、同じ入力、出力、アーキテクチャを持つ、モバイル向けにすでに最適化されている新しいモデルを見つけることです。たとえば:MobileNetおよびMobileBert。
アプリケーションバイナリサイズを削減する
Section titled “アプリケーションバイナリサイズを削減する”ONNX Runtimeバイナリサイズを削減するには、モデルに基づいてカスタムランタイムをビルドできます。
カスタムランタイムをビルドするプロセスを参照してください。
ORT形式変換の出力の1つは、モデルからの演算子とそのタイプのリストを含むビルド設定ファイルです。この設定ファイルを、カスタムランタイムバイナリビルドへの入力として使用できます。
事前ビルドパッケージとカスタムビルドの間のバイナリサイズの違いを示すために:
| ファイル | 1.18.0事前ビルドパッケージサイズ(バイト) | 1.18.0カスタムビルドサイズ(バイト) |
|---|---|---|
| AAR | 24415212 | 7532309 |
jni/arm64-v8a/libonnxruntime.so、圧縮解除 | 16276832 | 3962832 |
jni/x86_64/libonnxruntime.so、圧縮解除 | 18222208 | 4240864 |
このカスタムビルドは、ResNet50モデルを実行するために必要な演算子をサポートしています。ORT形式モデルの使用が必要です(--minimal_build=extendedでビルドされているため)。NNAPIおよびXNNPACK実行プロバイダーのサポートがあります。